Premessa
Per iniziare questo corso è richiesta una minima base di programmazione anche solamente procedurale in quanto tutti gli argomenti della programmazione ad oggetti verranno tratti in questo libro.
Alcuni argomenti verranno quindi dati per scontati e verrà sviluppata in maniera più approfondita la programmazione in c++
La versione di riferimento per il corso partirà dalla c++11 fino ad arrivare a trattare argomenti presenti nella versione c++17
Il manuale in questione nasce da una sintesi di un corso individuale in FAD fatto nel 2020 dal quale è stato preso spunto e rivisto.
Un po’ di storia
Prima di iniziare vale la pena di fare un po’ di storia del C++ per capire la sua evoluzione nel tempo. Il C++ è stato il padre dei linguaggi di programmazione dopo il suo predecessore C. E’ il primo che implementa la OOP, cioè la programmazione orientata agli oggetti, ed ha formato diverse generazioni di programmatori.
La prima release ufficiale del C++ è la C++98, anche se in realtà è nato nella metà degli anni 80. Per arrivare a una seconda release si arriva al 2011! Si deduce quindi che per quasi 26 anni, le basi del linguaggio sono rimaste sempre le stesse, formando quindi dei programmatori abbastanza radicati in quello che hanno appreso negli anni.
Dal 2011 ad oggi c’è stata una vera e propria esplosione di linguaggi di programmazione che se pur prendendo spunto anche dal C++ si sono a loro volta evoluti con concetti e semantica a volte superando il vecchio C++. Il C++ è passato da capostipite a inseguitore!
Dal 2011 si è quindi deciso di fare delle profonde modifiche che vengono rilasciate in ogni nuova release ogni 3 anni.
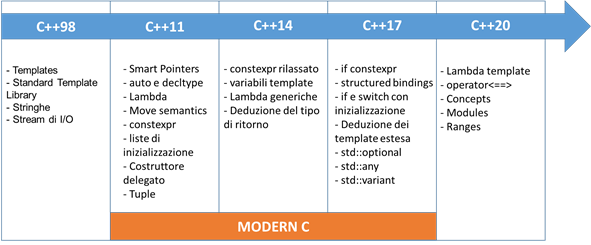
Dall’anno 2011 al 2017 si parla comunemente di Modern C ma la vera rivoluzione è stato il C++11 nel quale hanno aggiunto alcune keyword che mancavano di Java e C#. In questo periodo sta’ partendo il C++20. In questo corso verranno trattati solamente argomenti dal C++11 in poi.
Al contrario di Java che ha un sistema della gestione della memoria automatico che tiene traccia delle locazioni di memoria utilizzate e le libera solo quando non sono effettivamente più necessarie (garbage collector) in C++ questa gestione avveniva manualmente con dei vantaggi di velocità ma con la problematica di dover distruggere manualmente gli oggetti crati, dal Modern C in poi la memoria può essere gestita automaticamente
Scelta degli strumenti per iniziare
Per iniziare a scrivere del codice in C++ è opportuno scegliere un compilatore appropriato al sistema operativo utilizzato e una piattaforma IDE. In questi ultimi anni si sta’ sempre più affermando, come valido strumento di programmazione, Visual Studio Code.
Visual Studio Code è un editor di codice sorgente che può essere usato con vari linguaggi di programmazione, tra cui la famiglia di linguaggi C (C, C++, C#), F#, HTML e altri linguaggi web, tra cui PHP, Java, Ruby e molti altri. Incorpora un insieme di funzioni che variano a seconda del linguaggio che si sta usando.
Dopo aver affrontato tutti i primi concetti del C++ passeremo a programmare direttamente su QT, utilizzando QT Creator.
Per quanto riguarda il compilatore, in questo libro spiegheremo come installare e configurare MinGW sotto piattaforma Windows.
Installiamo MinGW e creiamo un primo progetto C++ in Visual Studio Code
In questo articolo vedremo come installare un compilatore per il linguaggio C e C++ in ambiente Windows (in particolare utilizzeremo un porting del compilatore GCC di Linux denominato MinGW) e creeremo un esempio di progetto C/C++ in Visual Studio Code.
I software che andremo ad installare e utilizzare (MinGW e Visual Studio Code) sono Open Source e rappresentano un’alternativa completamente gratuita al ben più costoso Microsoft Visual Studio (ciò vale se ci riferiamo limitatamente all’ambiente Windows).
Installiamo MingGW
MinGW (Minimalist GNU for Windows) è il porting in ambiente Windows del famoso compilatore GCC per Linux.
- Ada
- C
- C++
- Java
- Fortran
- Objective-C
MinGW in realtà è una collezione di compilatori tra i quali troviamo oltre che gcc per il codice C, anche g++ per il codice C++ e gfortran per Fortran. Per poter installare MinGW dobbiamo scaricare il file di installazione da questo indirizzo:
Otterremo un file di nome mingw-get-setup.exe il quale ci permetterà di scaricare ed installare l’ultima versione del software.
Facciamo doppio click sull’eseguibile e otterremo la seguente schermata:
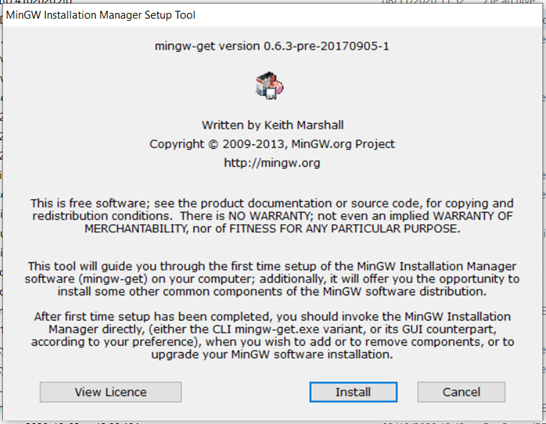
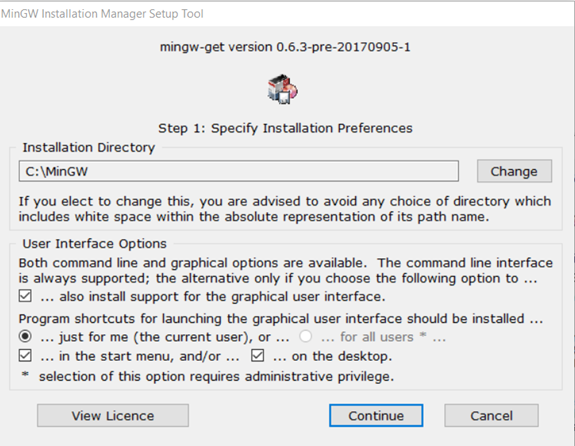
Procediamo con l’installazione lasciando tutte le impostazione inveriate avendo cura di selezionare il path desiderato per l’installazione
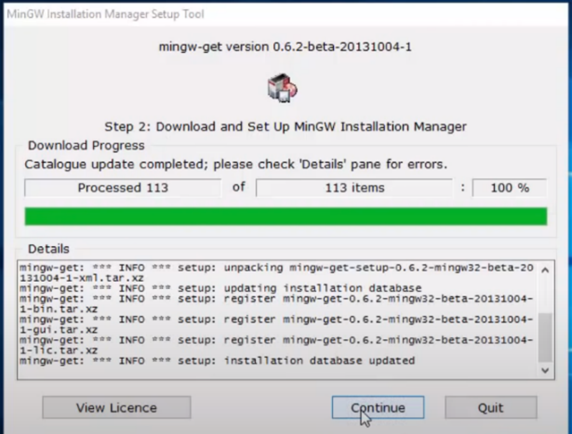
Viene effettuato un primo download per aggiornare il repository. Alla fine di questo premere il tasto Continue per andare a selezionare i pacchetti desiderati.
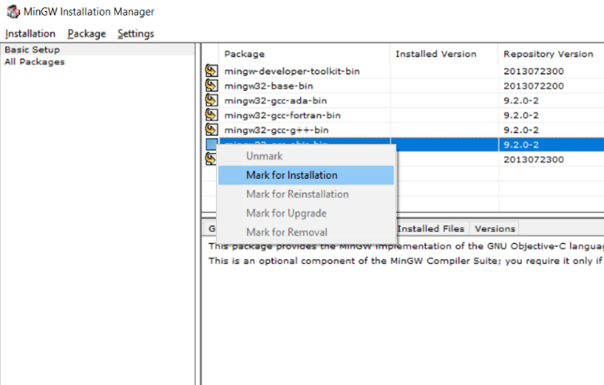
Selezionare i pacchetti del Basic Setup, andando su ogni voce con il tasto destro del mouse e selezionando Mark for Installation
Di seguito andare nel menù Installation -> Applay Changes per effettuare il download dei pacchetti desiderati
Al termine dell’installazione dovremo inserire il path degli eseguibili gcc e g++ (i comandi del compilatore GCC) all’interno della variabile d’ambiente Path di Windows:
Aggiungiamo il path dei binari di MinGW alla variaible d’ambiente Path. Se non abbiamo cambiato il percorso dobbiamo aggiungere il percorso C:\MinGW\bin alla variabile di sistema PATH
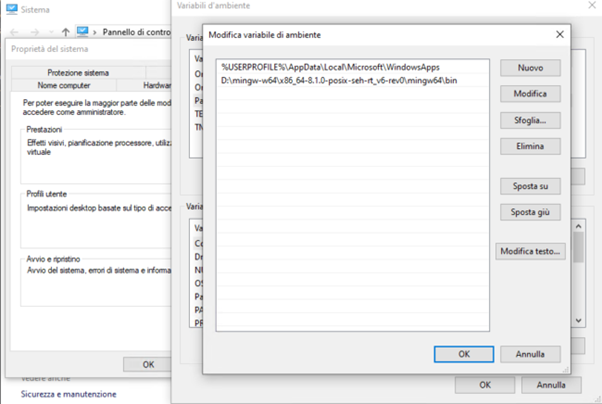
Una volta modificata la variabile d’ambiente possiamo aprire una console di windows (CMD) e lanciare il seguente comando:
gcc –v
Otterremo un output del tipo:
gcc version 8.1.0 (x86_64-posix-seh-rev0, Built by MinGW-W64 project)
Installiamo Visual Studio Code
Ora non ci resta che scaricare Microsoft Visual studio Code da questo indirizzo:
https://code.visualstudio.com/Download
Tra le varie opzioni di download, possiamo scegliere tra la versione a 32 e 64 bit, ed inoltre, possiamo scegliere tra una versioneUser Installer e System Installer: la differenza tra le due è che la versione User può essere installata anche senza avere i diritti di amministratore della macchina e verrà collocata nella cartella dell’utente che la sta installando.
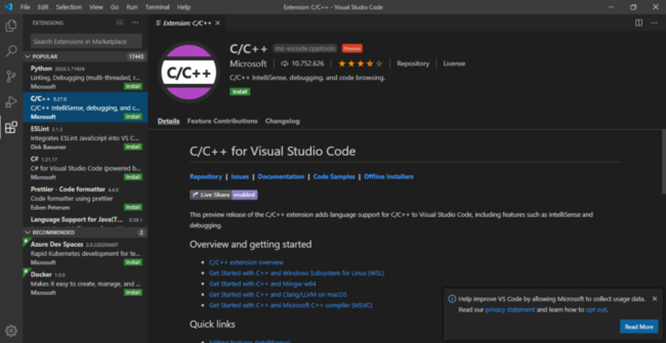
Una volta scaricato e installato Visual Studio Code, va aggiunta l’estensione C/C++ extension for VS Code. Questa può essere trovata cercando C++ extension nella vista Extension, come in figura
La vista Extension si trova nella barra laterale a sinistra, cercando in Search Extension in Marketplace con la chiave C++ extension troveremo il plugin
Adesso possiamo creare il nostro progetto C++, apriamo un prompt dei comandi e ci posizioniamo in una cartella di nostra preferenza (ad esempio Documenti), digitiamo i seguenti comandi MSDOS:
mkdir VSCProjects
cd VSCProjects
mkdir firstProject
cd firstProject
code .Con l’ultima istruzione code. viene lanciato Visual Studio Code impostando la directory firstProject come workspace. Una volta in Visual Studio Code possiamo utilizzare il terminale integrato cliccando dal menù principale in alto su Terminal > New Terminal.
Fondamentali per le successive fasi di compilazione e di debugging del progetto sono i seguenti file JSON che si trovano nella cartella .vscode (vedremo successivamente come generarli in automatico):
- tasks.json (istruzione per il build)
- launch.json (impostazioni del debugger)
- c_cpp_properties.json (impostazioni del compiler path e di IntelliSense)
Creiamo il primo file cpp e compiliamo il nostro progetto
Installato Visual Studio Code vediamo ora come creare un progetto C++ che compileremo usando MinGW. Creiamo un file c++ nel nostro workspace cliccando sul bottone New File
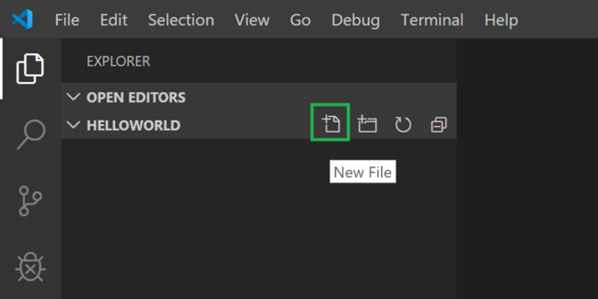
Chiamiamo il nuovo file helloworld.cpp e scriviamo il seguente codice:
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main() {
vector<string> msg {"Hello", "C++", "World", "from", "AppuntiSoftware.it!"};
for (const string& word : msg) {
cout << word << " "; }
cout << endl;
}A questo punto dobbiamo creare il file task.json che si occupa di fare il build del nostro semplicissimo progetto. Dalla barra del menù in alto, scegliamo Terminal > Configure Default Build Task, si aprirà la seguente schermata:

Scegliamo g++.exe build active file
Cliccando su C/C++: g++.exe build active file verrà generato il seguente file:
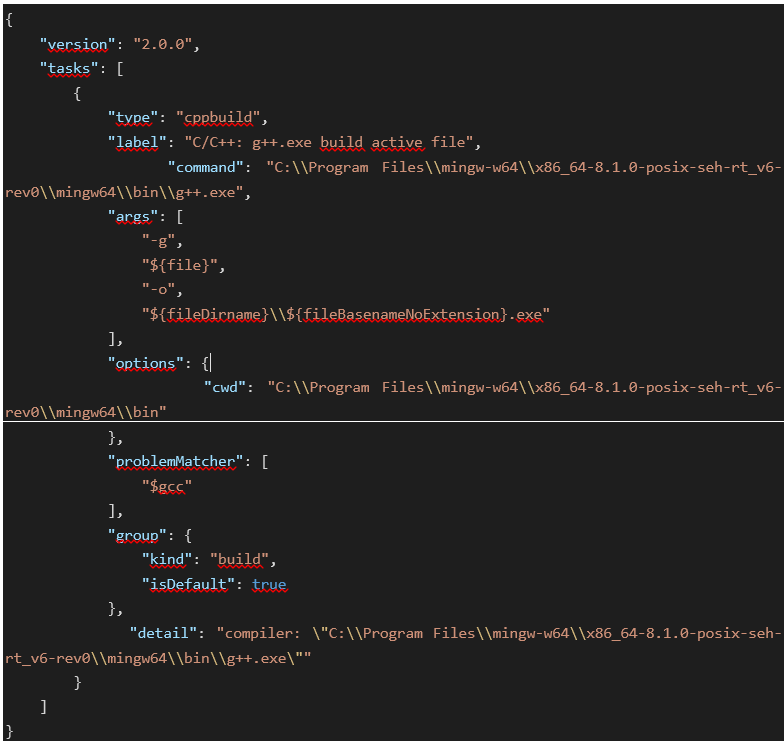
Le variabili Command e cwd saranno diverse a seconda di dove è stato installato MinWG. Possiamo omettere il percorso di g++.exe in quanto già inserito nella PATH
Debugging
Se volessimo provare a debuggare l’applicazione appena creata, dobbiamo per prima cosa creare il file launch.json. Dal main menu in alto clicchiamo su Run > Add Configuration… e poi scegliamo C++ (GDB/LLDB), vedremo elencate una serie di configurazioni di debugger, scegliamo g++.exe build and debug active file.come mostrato in figura:
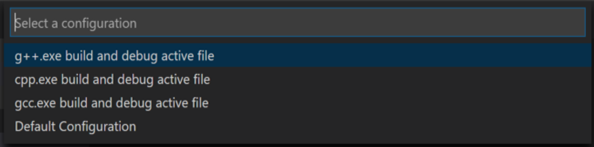
Creiamo il file launch.json per abilitare il debugger
Viene successivamente creato il file launch.json:
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "(gdb) Launch",
"type": "cppdbg",
"request": "launch",
"program": "${fileDirname}\${fileBasenameNoExtension}.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "C:\Program Files\mingw-w64\x86_64-8.1.0-posix-seh-rt_v6-rev0\mingw64\bin\gdb.exe",
"setupCommands": [
{
"description": "Abilita la riformattazione per gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
]
}
]
}Se tutte le operazioni fin qui spiegate sono andate a buon fine siamo ora pronti per iniziare il nostro primo modulo partendo con la programmazione C++!
Iniziamo con il C++
Il C++ è un linguaggio molto potente e permette quindi di poter fare molte cose rispetto ad altri linguaggi di programmazione. In questo corso evidenzieremo quindi anche i possibili errori a cui solitamente si va in contro e che spesso causano crash o allocazioni di memoria esorbitanti che rischiano di rendere molto pesante anche una semplice applicazione. Un buon codice è indispensabile per eliminare problemi nel presente ma anche nel futuro, quando magari bisognerà rimettere mano a quando scritto in precedenza.
Risorse on-line
Documentazione
Per quanto riguarda il C++, tutto quello che si vuole sapere è disponibile su internet e i due siti ufficiali a qui fare sempre riferimento sono i seguenti:
Cpp Reference – https://en.cppreference.com/w/
Cpp Core Guidelines – https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines
Compilatori Online
Come spiegato in precedenza, nella prima parte del corso, utilizzeremo Visual Studio Code precedentemente configurato. E’ però utile menzionare alcune risorse online molto utili per iniziare, che permettono di scrivere del semplice codice e verificarne immediatamente il funzionamento
Coliru – http://coliru.stacked-crooked.com/
Cpp.sh – http://cpp.sh/
Online Gdb – https://www.onlinegdb.com/
Cpp Insight – https://cppinsights.io/
GodBolt – https://godbolt.org/
OnlineGDB.com è un compilatore in linea e uno strumento di debugger per i linguaggi C/C++. È il primo IDE online al mondo che offre funzionalità di debug con debugger gdb incorporato. Questa è un’app web molto utile per i programmatori che amano la codifica nell’IDE online ma affronta arresti anomali imprevisti e bug complicati nel loro codice. OnlineGDB fornisce potenza di debug a tali utenti per aiutarli.
Coliru, rispetto a Online Gdb è più veloce a compilare ma quest’ultimo ha il controllo della sintassi durante la scrittura del codice, cosa che può aiutare parecchio durante la scrittura.
Cpp Insight, al contrario dei primi due, non è un vero e proprio compilatore, ma è uno strumento che ti permette di visualizzare il codice intermedio che viene generato dal compilatore, questo in alcuni casi può servire.
GodBolt, come Cpp Insight permette di visualizzare il codice macchina del sorgente scritto. E’ possibile scegliere tra decine di compilatori per capire cose effettivamente cambia tra un compilatore e l’altro.
Puntatori e Reference
Variabili
In C++ una variabile è un indirizzo di memoria che contiene un valore.
Il classico esempio:
int a=5;
La variabile a ha valore 5, ma ha anche un indirizzo di memoria. Gli operatori Addres-of e Dereference servono a ritornare il valore di una variabile dato il suo indirizzo di memoria o il suo indirizzo di memoria dato il suo valore
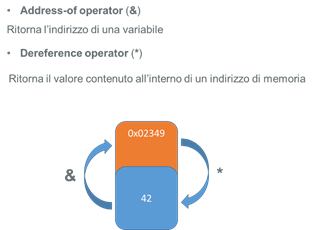
Se volessimo sapere a che indirizzo di memoria è contenuto il valore della variabile a si esegue il seguente codice
#include
int main(int argc, char const *argv[])
{
int a=5;
std::cout << a << std::endl;
std::cout << &a << std::endl;
return 0;
}Che produrrà il seguente output:
5
0x61fe1cCome si può notare anteponendo & viene stampato l’indirizzo di memoria.
Una cosa importantissima da ricordare sempre è che le variabili non vengono inizializzate di default.
Fare quindi
int a;
Non ci dà la certezza che a abbia un valore di default (come ad esempio avviene su Java dove verrebbe impostata a 0 per default). In C++ la variabile a potrebbe avere qualsiasi valore.
I puntatori
Tratteremo in maniera molto rapida il discorso dei puntatori e delle reference in quanto solo per esse ci vorrebbe un corso a parte!
Esiste un altro tipo di variabile che si chiama puntatore il quale è a sua volta una variabile che al suo interno, come valore, non ha un numero ma ha un indirizzo di memoria. Possiamo immaginarlo come un classico “link del desktop”. Questo implica che se si cancella un puntatore NON viene cancellato il dato in quanto è solo una variabile che punta al contenitore; così come quando viene cancellato il link sul desktop dove in realtà non si sta effettivamente cancellando il file a qui punta.
Vediamo ora come viene dichiarato e inizializzato un puntatore
#include
int main(int argc, char const *argv[])
{
int a=5;
// dichiarazione e inizializzazione di un puntatore
int* p = &a;
std::cout << a << std::endl;
std::cout << &a << std::endl;
std::cout << p << std::endl;
std::cout << *p << std::endl;
return 0;
}In questo esempio viene creata una variabile a, un puntatore p e viene assegnato a p l’indirizzo di memoria che contiene a. Successivamente vengono stampati a video
– il valore della variabile a
– l’indirizzo di memoria in cui è allocato il valore di a, con &a
– l’indirizzo di memoria a cui punta il puntatore p (che poi è lo stesso di a int* p = &a; )
-Il valore che è presente all’indirizzo di memoria p (*p)
l’output sarà
5
0x61fe14
0x61fe14
5Per inizializzare un puntatore vuoto:
int* a = nullptr
Anche in questo caso, come per le variabili, è importantissimo inizializzare sempre i puntatori, in quanto altrimenti avrebbero degli indirizzi di memoria casuali. Il nullprt è stato implementato da C++11 in poi.
I puntatori si utilizzano principalmente per ottimizzare la memoria. Nel caso di un puntatore a una semplice variabile int non si capisce il vantaggio ma quando si inizia ad utilizzare i puntatori per le classi allora si capisce subito che il risparmio di memoria è notevole.
E’ molto meglio istanziare un oggetto che punta a una classe che farne la sua copia in memoria; ma queste cose le vedremo più tardi.
Le reference
Oltre ai puntatori esiste un altro tipo di dichiarazione delle variabili e sono le reference.
La reference di C++ e come se fosse un alias di un’altra variabile. A differenza del puntatore, se io cancello la reference io distruggo l’oggetto. Il puntatore è un’altra variabile, la reference NO.
La differenza tra puntatori e reference è la stessa che c’è in Linux tra soft link e hard link. Se in linux cancelliamo un soft link a un file, il file non viene cancellato (puntatore) , mentre, se cancelliamo un hard link, viene cancellato anche il file (reference).
Es:
//Assegno un valore ad a
int a = 10;
//Creo una reference refa che è uguale ad a
int& refa = a;
//Cambio il valore a refa
refa = 55;
//Stampo il valore di refa
std::cout << "refa=" << refa << std::endl;
//Di conseguenza è variato anche a
std::cout << "a=" << a << std::endl;In questo caso il simbolo & viene utilizzato per creare una reference e non è da confondere con l’operatore & che indica l’indirizzo di memoria a cui punta una variabile.
Vediamo ora un esempio che riassume un po’ tutto:
#include <iostream>
int main(int argc, char const *argv[])
{
//Assegno un valore ad a
int a = 10;
//Creo un puntatore pointa che punta all'indirizzo
//di memoria della variabile a
int* pointa = &a;
//Creo una reference refa che è uguale ad a
int& refa = a;
//Stampo il valore di pointa antecedendo *
std::cout << "*pointa="<< *pointa << std::endl;
//Cambio il valore all'indirizzo di memoria a
// cui punta pointa
*pointa = 33;
//Stampo il valore di *pointa
std::cout << "*pointa="<< *pointa << std::endl;
//Di conseguenza ho cambiato il valore di a
std::cout << "a=" << a << std::endl;
//Cambio il valore a refa
refa = 55;
//Stampo il valore di refa
std::cout << "refa=" << refa << std::endl;
//Di conseguenza è variato anche a
std::cout << "a=" << a << std::endl;
return 0;
}
L’output sarà
*pointa=10
*pointa=33
a=33
refa=55
a=55
Come si nota abbiamo creato un puntatore (pointa) e una reference (refa)rispettivamente con int* pointa; e int& refa =a;
Abbiamo poi usato gli operatori Address operator e Dereference operator in altri contesti:
- Per assegnare al puntatore pointa, l’indirizzo di memoria dove si trova il valore di a abbiamo usato il Address operator (int*pointa = &a;)
- Per stampare il valore a cui punta il putatore pointa abbiamo usato il Dereference operator (std::cout << “*pointa=”<< *pointa << std::endl;)
Si può giocare molto con i puntatori e con le reference ma la manipolazione eccessiva, nel C++ moderno, non serve e si cerca di evitare.
Il cast
Il cast è una conversione di tipo di una variabile. Una conversione di tipo è un’operazione volta a trasformare un valore di un certo tipo in un valore di un altro tipo.
Questa operazione è comune in tutti i linguaggi.
Quando in un’espressione si utilizzano tipi di dati diversi può nascere il problema della conversione di tipo, che chiaramente non c’è per dati dello stesso tipo.
La conversione che viene eseguita dal compilatore stesso viene chiamata implicita, mentre la conversione decisa dal programmatore viene chiamata esplicita.
I tipi di cast in C++ sono 4
Facciamo subito degli esempi per capire i concetti.
Casting implicito
Le conversioni implicite non richiedono nessun operatore per essere eseguite, ma sono eseguite in automatico.
#include <iostream>
int main() {
int x=8, y=3;
float divisione;
divisione=x/y;
std::cout<<"La divisione e': "<<divisione;
return 0;
}
Questo programma darà come risultato 2 anziché 2,67. Questo perché ha effettuato un’operazione di casting implicito da float a int. Questa conversione ha procurato una perdita di precisione, in particolare è stata scartata la parte frazionaria.
Facciamo un altro esempio di casting in C++:
#include <iostream>
using namespace std;
int main() {
int base, altezza;
float area;
cout<<"Calcoliamo l'area del triangolo, inserisci la base: ";
cin>>base;
cout<<"Adesso inserisci l'altezza: ";
cin>>altezza;
area=base*altezza/2;
cout<<"L'area e': "<<area;
return 0;
}
In questo esempio prendiamo la base e l’altezza di tipo intero e poi le utilizziamo per calcolare l’area che però è di tipo float. Anche qui si ha una perdita di precisione.
Se inseriamo ad esempio i valori: base=5 e altezza=3 otterremo area=7.
Cast Esplicito
Continuiamo a parlare del casting in C++ introducendo il concetto di casting esplicito.
Nel casting esplicito l’operatore di cast è rappresentato in questo modo:
b=float(a); //notazione C++ Questo è il cast C Style, che non viene più utilizzato
Static cast
Nelle versioni più recenti l’operazione di casting si rappresenta con static_cast. (e buona norma usare questi tipi di cast più recenti)
La sintassi è questa:
static_cast <tipo> (espressione) dove tipo è indicato tra due parentesi angolari < e >
espressione è racchiusa tra parentesi tonde e rappresenta l’espressione o la variabile da convertire.
Esempio
int main()
{
double b = 1.5;
int a = static_cast<int>(b);
std::cout << a;
return 0;
}
Nello static cast se la conversione non è valida il sorgente non compila. Il controllo dello static viene fatto durante la compilazione (compile time).
Reinterpret cast
Nel reinterpret cast il compilatore non controlla il cast ed è demandata al programmatore la responsabilità del cast. E’ molto simile al vecchio cast del C, dove anche in questo caso il compilatore non verificare il cast
Non viene quasi mai utilizzato.
reinterpret_cast <tipo> (espressione)
Esempio
int main()
{
int a = 123;
double* p = reinterpret_cast<double*>(&a);
return 0;
}
Questa conversione genererebbe, giustamente, un errore di compilazione se sostituissimo l’operatore reinterpret_cast con quello di conversione statica.
Nell’implementazione dell’operatore di conversione in stile C del linguaggio C++, reinterpret_cast è l’ultima spiaggia, impiegato laddove tutti gli altri operatori di conversione sono inapplicabili.
Tuttavia, anche l’applicabilità di questo operatore ha dei limiti. Ad esempio, esso non ha efficacia sui qualificatori const e volatile, per i quali è necessario ricorrere all’uso di const_cast.
Nella maggior parte dei casi, inoltre, lo standard garantisce che la riconversione al tipo originale ripristina il valore originale. Tuttavia, questa regola è soggetta a variabilità in base al compilatore in uso, in particolare quando la conversione è applicata a puntatori a metodi membri di classe.
Namespace
Più familiarizziamo con un linguaggio di programmazione e più tendiamo ad assumere una certa pratica nel prevenire gli errori più banali. Ad esempio, una delle cose che impariamo subito è che non possiamo usare nessuna delle parole riservate del linguaggio per nominare i simboli del nostro programma.
Sappiamo, inoltre, che dobbiamo evitare di usare due volte lo stesso nome nello stesso ambito di visibilità, e che dobbiamo stare attenti a non oscurare una variabile “esterna” creandone una nuova.
Siamo quindi abituati a tutta una serie di vincoli e restrizioni che, anche se non in maniera severa, ci condizionano nella scelta dei nomi di variabili e funzioni, e di tutte le altre entità che vedremo meglio nel seguito.
Tuttavia, non siamo gli unici a decidere quali nomi usare.
Pensiamo ad esempio alle operazioni di I/O per le quali ci serviamo di librerie già esistenti. Anche in questo caso, infatti, escludiamo tutti i simboli definiti in esse dal bacino delle nostre possibilità. In caso di conflitti, quindi, può essere necessario un pesante intervento di refactoring per risolvere quello che dovrebbe essere un banale problema di integrazione.
Per questo motivo, C++ mette a disposizione un costrutto apposito per la definizione di gruppi di nomi indipendenti gli uni dagli altri: i namespace.
La sintassi per la definizione di un namespace è la seguente:
namespace <nome>
{
// definizione dei simboli
...
}
I simboli definiti dentro il namespace sono protetti da ingerenze esterne e allo stesso modo evitano di “invadere” lo spazio dei nomi di altre librerie. Lo stesso namespace può essere usato più volte, ad esempio quando i nostri simboli sono sparsi su più di un file, avendo cura di usare sempre lo stesso nome (rispettando maiuscole e minuscole). La figura seguente mostra, a titolo esemplificativo, l’uso dello stesso namespace test su più file, anche ripetuto più volte nello stesso file.
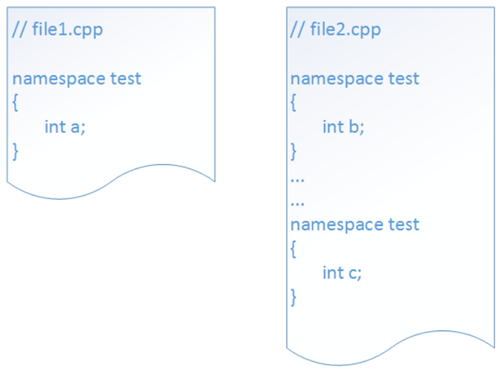
L’esempio successivo mostra una semplice applicazione dei namespace. Supponiamo di voler implementare due funzioni di utilità per la stampa di numeri in formato esadecimale e binario. Possiamo definire due namespace distinti, Hex e Bin, per le nostre funzioni di stampa. Per entrambe possiamo permetterci di usare lo stesso nome, printNumber, per dare un certo carattere di omogeneità alle nostre API.
#include <iostream>
#include <bitset>
namespace Hex
{
int base = 16;
void printNumber(int value)
{
std::cout << std::hex << value << std::dec << std::endl;
}
}
namespace Bin
{
int base = 2;
void printNumber(int value)
{
std::cout << std::bitset<32>(value) << std::endl;
}
}
int main()
{
int a = 123456;
Hex::printNumber(a);
Bin::printNumber(a);
std::cout << Hex::base << std::endl;
std::cout << Bin::base << std::endl;
return 0;
}
Per invocare le due funzioni nel main usiamo l’operatore di risoluzione di scope, identificato dai caratteri ::, che ci consente di accedere ai simboli definiti entro i rispettivi namespace.
Tralasciamo per il momento i dettagli implementativi delle due funzioni, che riguardano le varie opzioni di I/O della libreria iostream e quelle di bitset per la manipolazione di bit, per le quali si rimanda all’apposita documentazione.
La vita utile delle variabili definite dentro un namespace, al pari di quelle globali, concide con l’intera durata del programma. Ciò significa che esse risiedono nei segmenti di memoria Data segment o BSS a seconda che siano state inizializzate o meno. In questo caso, le due variabili base, definite nei rispettivi namespace, sono quindi sempre disponibili in qualunque contesto.
Risolvere le ambiguità dell’uso di namespace
Nell’esempio precedente l’invocazione diretta della funzione printNumber, senza cioè fare riferimento ad uno dei namespace in cui sono definite, produrrebbe un errore di compilazione, poichè il compilatore cercherebbe una funzione con questo nome definita in ambito globale.
Alcuni compilatori, ad esempio g++, potrebbero segnalare la presenza di funzioni candidabili, cioè con questo nome, definite all’interno di namespace, ma la compilazione verrebbe interrotta ugualmente poichè, anche in questo caso, il compilatore da solo non saprebbe quale delle due usare.
Tuttavia, a volte non è necessario fare riferimento nello stesso frammento di codice a simboli contenuti in namespace differenti, ed in questo caso, il continuo uso dell’operatore di risoluzione di scope sarebbe superfluo, oltre che prolisso.
A questo scopo è utile ricordare la clausola using namespace, la quale indica in maniera esplicita al compilatore di tenere in considerazione i simboli definiti in un namespace durante la compilazione, così da risolvere le possibili ambiguità.
Nell’esempio successivo, modifichiamo il contenuto della funzione main con l’uso di questa clausola. Nel primo ambito di visibilità, nel quale usiamo il namespace Hex, la prima invocazione di printNumber stamperà un valore esadecimale. Successivamente, creando un nuovo ambito di visibilità all’interno del quale invece imponiamo l’uso dei simboli definiti in Bin, stamperà una sequenza di bit.
// definizione dei namespace Hex e Bin
...
int main()
{
int a = 123546;
{
using namespace Hex;
printNumber(a); // esacedimale
}
{
using namespace Bin;
printNumber(a); // binario
}
return 0;
}
Questo esempio funziona perchè i due ambiti di visibilità sono indipendenti. Se fossero stati annidati, vi sarebbe stata comunque una intersezione tra i due spazi di nomi Hex e Bin, visto l’uso del medesimo simbolo printNumber, e pertanto sarebbe stato necessario ricorrere nuovamente all’uso dell’operatore ::.
L’uso frequente dei simboli definiti nella libreria iostream fornisce un altro esempio dell’utilità di using namespace. Nell’esempio precedente, aggiungere la clausola seguente ci avrebbe consentito di rimuovere ogni occorrenza del prefisso std::, e di ottenere quindi un listato più leggibile.
// include
...
using namespace std;
// definizione dei namespace Hex e Bin
...
È inoltre possibile restringere l’applicazione della clausola using a singoli elementi del namespace, con una clausola del tipo:
using Hex::base;In questo caso possiamo omettere il prefisso Hex:: per il solo simbolo base, mentre per specificare quale funzione printNumber usare si dovrà ricorrere all’operatore di risoluzione di scope, così come per accedere alla variabile base definita in Bin.
Gli Header (.h) e i .cpp
In C++ i file si dividono in header (.h) e in .cpp
Un header file (o file di intestazione) è un file che aiuta il programmatore nell’utilizzo di librerie durante la programmazione. Un header file del linguaggio ANSI C è un semplice file di testo che contiene i prototipi delle funzioni definite nel relativo file .cpp. I prototipi permettono al compilatore di produrre un codice oggetto che può essere facilmente unito (detto volgarmente “linkato“) con quello della relativa libreria in futuro, anche senza avere la libreria sottomano al momento.
Es:
#include<iostream>
#include<vector>
…
Gli HEADER file contengono solamente le definizioni e le dichiarazioni delle classi e delle funzioni mentre nei files .cpp sono contenute le sue implementazioni
Facciamo un esempio
prova.h
#ifndef PROVA_H
#define PROVA_H
void pippo();
#endif // PROVA_H
prova.cpp
#include "prova.h"
void pippo(){
int a=6;
a++;
}
main.cpp
#include <iostream>
#include "prova.h"
int main()
{
pippo();
return 0;
}
In prova.h abbiamo solamente definito la funzione pippo(), mentre in prova.cpp ne abbiamo sviluppato la sua implementazione.
Nel main.cpp abbiamo solamente incluso il file prova.h per utilizzare la funzione pippo(). Noi in realtà non sappiamo cosa è contenuto in essa ma la possiamo utilizzare in quanto dichiarata in prova.h
Quando andiamo ad istallare delle librerie, vengono forniti solamente i .h mentre i cpp vengono nascosti
Ma perché in C++ si fa questo?
Il .h è il file che viene reso visibile e che non contiene la parte implementativa del codice; mentre il cpp che verrà successivamente nascosto, diventa la parte compilata e andrà a far parte delle librerie, non sapremo quindi cosa è stato fatto per implementare il codice ma ne conosciamo solamente i modi per utilizzarlo, che sono appunto visibili nel .h
Questo sistema è il motivo per cui il C++ è più veloce rispetto ad altri linguaggi di programmazione; Quando si lavora su un mono file, il tuo codice sorgente viene preso dal compilatore, compilato, creato un codice intermedio e linkato. Molti linguaggi di programmazione lavorano su un file unico e ogni volta che si effettua una singola modifica al sorgente bisogna ricompilare tutto! In C++, utilizzando gli header e cpp, questo non è necessario.
In C++, se si va a modificare solamente il .cpp per variare l’implementazione di un codice, non è necessario ricompilare tutto ma solamente il .cpp che è stato modificato. Mentre se si va a modificare la definizione del codice nel .h bisognerà andare a ricompilare tutti i file che includono quel .h. Nel caso dell’esempio precedente, se andiamo ad aggiungere una funzione topolino() del file prova.h bisognerà ricompilare sia prova.cpp che main.cpp in quanto includono prova.h
Utilizzando questa logica, su sorgenti molto grandi, cambiano pesantemente i tempi di compilazione, rendendo il C++ più veloce rispetto ad altri linguaggi in questa fase.
Nei file .h nessuno vieta di fare delle piccole implementazioni ad esempio
#ifndef PROVA_H
#define PROVA_H
#include <iostream>
void pippo();
void topolino{
std::cout << "ciao" << endl;
}
#endif // PROVA_H
Ma come abbiamo già detto, se questa implementazione viene modificata dobbiamo poi andare a ricompilare tutti i files che includevano questo .h
I vettori
Nel “vecchio” linguaggio C, è possibile strutturare i dati in due modi: usando struct oppure usando gli array. Questi ultimi però hanno delle limitazioni. In particolare, la dimensione di un array deve essere nota a tempo di compilazione. Per ovviare a questa limitazioni, in C++, uno dei concetti più importanti presenti nella libreria standard è quello di contenitore. Un contenitore non è altro che un oggetto che può contenere altri oggetti. Il contenitore più semplice di tutti è il vector, che emula il comportamento di un semplice array C, aggiungendo tutta una serie di funzionalità. Per creare un oggetto “vettore” bisogna prima di tutto specificare il tipo di dato che può contenere. Per esempio, se vogliamo creare un vettore di interi, scriviamo così.
#include<iostream>
#include<vector>
int main(int argc, char const *argv[])
{
std::vector<int> v;
return 0;
}
La variabile v è un contenitore inizialmente vuoto, cosa che nel caso dei vector può essere fatta.
Esistono vari modi di inizializzare un vector, se volessi un vettore di 10 elementi, posso scrivere così:
std::vector<int> v1(10);Se voglio inizializzarlo con dei valori iniziali, posso scrivere così:
std::vector<int> v1 = {1,2,3,45,32};
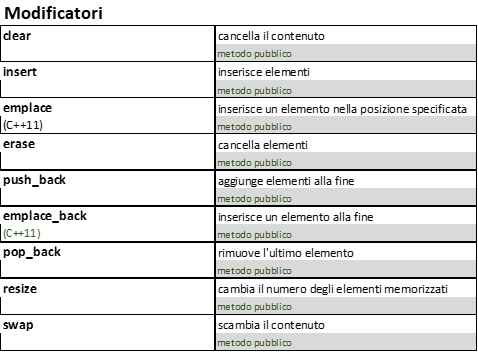
Vediamo brevemente i modificatori di vector ( en.cppreference.com/w/cpp/container/vector )